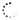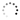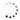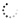batchUpdate() works on values if you use sheet.values().batchUpdate() and works on sheet properties if you use sheet..batchUpdate()
So I wanted to be notified for my tradingBot (made in Python), if a certain KPI was met. On my Mac, no problem. I use Notify.
from notifypy import NotifyBut I wanted to receive a notification even when I am not sitting at my computer. I figured with the help of Google I could achieve this. So I write to a Google Sheet some values and there I trigger an AppScript which sends me an email if KPI is met.
First attempt:
values = [[datetime, last, change, gain, loss, rsi]]
part1 = {
'values': values
}
result = sheet.values().update(
spreadsheetId=SAMPLE_SPREADSHEET_ID, range="Sheet1!A2:F2",
valueInputOption="RAW", body=part1).execute()
values = [["insert into ticker (datetime, last, change,gain,loss) values ( '{}',{:f} ,{:f} ,{:f}, {:f} )".format(
datetime, last, change, gain, loss, rsi)]]
part2 = {
"values": values
}
result = sheet.values().update(
spreadsheetId=SAMPLE_SPREADSHEET_ID, range="Sheet1!A5",
valueInputOption="RAW", body=part2).execute()execute() was called twice, for each row I update. Hence triggering the AppScript (which sends an email) twice. I always wondered why I receive duplicates. Couldn’t figure it out.
Then I received a warning from Google: too many emails sent, with some sort of Log

So I saw: aha, it actually calls the “myFunction” twice. I immediately knew it had to do with how I update the sheet.
I quickly figured there’s a “batchUpdate” function. But documentation was awfully bad. Sheets does know 2 different kind of requests. One kind updates the sheet’s properties (colours/rows, design stuff). The other updates it’s values. BUT they don’t tell that very explicitly. By luck I figured it works like this:
values = [datetime, last, change, gain, loss, rsi]
part1 = {
"range": "Sheet1!A2:F2",
"values": [
values
]
}
values = [["insert into ticker (datetime, last, change,gain,loss) values ( '{}',{:f} ,{:f} ,{:f}, {:f} )".format(
datetime, last, change, gain, loss, rsi)]]
part2 = {
"range": "Sheet1!A5",
"values": values
}
requests = {
"valueInputOption": "RAW",
"data": [
part1, part2
]
}
sheet.values().batchUpdate(spreadsheetId=SAMPLE_SPREADSHEET_ID,
body=requests).execute()and the important part is the “.values()” part in the last line. I first tried without it and Google told me: don’t know range, don’t know data, don’t find fields and other stuff.
As soon as I added the .values() it worked seamless
Looking forward to your comments